Tuning Spark Applications
February 18, 2017 Leave a comment
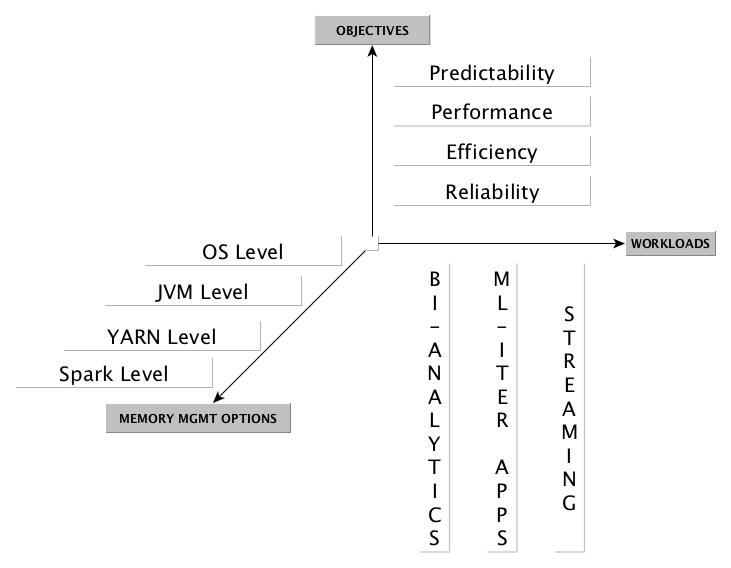
Tuning performance of Spark Applications can be done at various stages
- OS Level
- JVM Level
- YARN Level
- Spark Level
OS Level
In yarn-site.xml, we can allocate physical and virtual memory for a container initialized the node.
https://tekmarathon.com/2017/02/13/important-yarn-configuration-properties/
JVM Level
We can look at the performance of the JVM Garbage Collection and then fine tune GC parameters
./bin/spark-submit –name “My app” –master yarn –conf spark.eventLog.enabled=false –conf “spark.executor.extraJavaOptions=-XX:OldSize=100M -XX:MaxNewSize=100M -XX:+PrintGCDetails -XX:+PrintGCTimeStamps” myApp.jar
http://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html
YARN Level
While submitting the job, we can control
Number of executors (Executor is run inside container and 1 Executor per Container)
Memory for each executor
Number of cores for each executor (This value can be raised to a maximum of 2x times the actual cores, but beaware that it can also raise the bar for memory)
Memory Overhead
./bin/spark-submit –name “My app” –master yarn –num-executors 8 –executor-memory 4G –executor-cores 16 –conf “spark.yarn.executor.memoryOverhead=1024M” myApp.jar
https://hadoop.apache.org/docs/r2.7.1/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
Spark Level
Prior to Spark 1.6.0, executor memory (spark.executor.memory) was split into two different pools
Storage Memory: Where it caches RDDs
Execution Memory: Where it holds execution objects
From 1.6.0 onwards, they are combined into a unified pool and there is no hard line split between the two. It is dynamically decided at run time on ratio of memory allocation for these two pools.
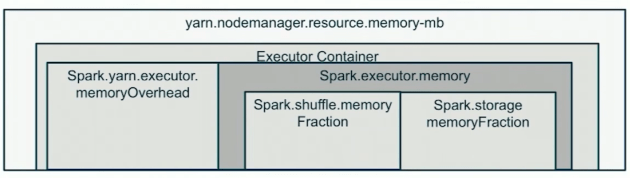
https://0x0fff.com/spark-memory-management/
Based on all the above factors, we should target tuning the memory settings based on
- Objectives (EFFICIENCY vs RELIABILITY) and
- Workloads (whether its a BATCH/STREAMING)

Some TIPS:
- Cost of garbage collection is directly proportional to the number of objects hence try to reduce number of objects (for example use Array(int) instead of List)
- For Batch Applications use default GC (ParallelGC) and for Streaming Applications use ConcMarkSweepGC
// BATCH Apps: default GC -XX:+UseParallelGC -XX:ParallelGCThreads=<#> // Streaming Apps -XX:+UseConcMarkSweepGC -XX:ParallelCMSThreads=<#> OR // G1 GC Available from Java7, which is considered as good replacement to CMS --XX:+UseG1GC
- KRYO Serialization: This is 10x times faster than Java Serialization. In general, for 1G disk file, it takes 2-3G to store it into memory which is is the cost of Java Serialization.
conf.set("spark.serializer", "org.apache.spark.serializer.KyroSer");
// We need to register our custom classes with KYRO Serializer
- TACHYON: Use tachyon for off-heap storage. The advantage is that even if the Executor JVM crashes, it stays in the OFF_HEAP storage.
References:
https://www.youtube.com/watch?v=dTR30Fy02Yo&t=19s

{kind=link}
Recent Comments