Different Similarity/Distance Measures in Machine Learning
November 15, 2015 Leave a comment
What is the best similarity/distance measure to be used in machine learning models? This depends on various factors. We will see each of them now.
Distance measures for numeric data points
Minkowski Distance: It is a generic distance metric where Manhattan(r=1) or Euclidean(r=2) distance measures are generalizations of it.
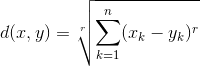
Manhattan Distance: It is the sum of absolute differences between the coordinates. It is also called as Rectilinear Distance, L1-Distance/L1-Norm, Minkowski’s L1 Distance, City Block Distance, Taxi Cab Distance.
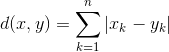
Euclidean Distance: It is the square-root of sum of squares of difference between the coordinates and is given by Pythagorean theorem. Also called as L2 Norm, Ruler Distance. In general, default distance is considered as Euclidean distance.
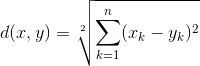
Use Manhattan or Euclidean distance measures if there are no missing values in the training data set (data is dense)
Cosine Similarity
This measures the cosine of angle between two data points (instances). It is a judgment of orientation rather than magnitude between two instances/vectors with respect to the origin. The cosine of 0degrees is 1 which means the data points are similar and cosine of 90degrees is 0 which means data points are dissimilar (all these angular measures are independent of magnitude).
- Mostly used in high dimensional positive spaces where output is bounded in the range of [0,1].
- Used in Information Retrieval, Text Mining, Recommendation Systems and Classifications. It is also used to measure cohesion between the clusters in Data Mining.
- It is very efficient to evaluate sparse vectors(as only the non-zero dimensions in the space are considered)
- If the attribute vectors are normalized by subtracting the vector means [e.g., Ai – mean(A)], the measure is called centered cosine similarity and is equivalent to the Pearson Correlation Coefficient.
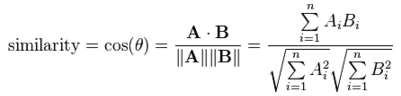
Disadvantage: Cosine similarity is subjective to the domain and application and is not an actual distance metric. For example data points [1,2] and [100,200], are shown similar with cosine similarity, whereas in eucildean distance measure shows they are far away from each other (in a way not similar).
Question #1: If we want to find out closest merchants (like costco, walmart, delta, starbugs, etc) to a given merchant, we would go for cosine similarity because we want merchants in similar domains (i.e, orientation) rather than the magnitude of the feature vector.
Question #2: If we want to find out closest customers to a given customer, we would go for euclidean distance because we want customers who are close in magnitude to the current customer.
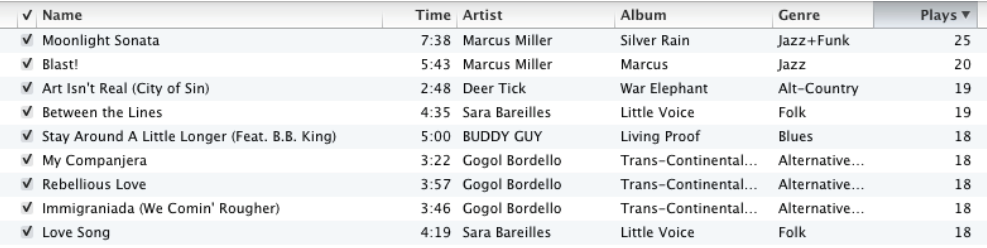
Pearson Correlation Coefficient
This is a measure of correlation between two random variables. It ranges between [-1, 1]. 1 is the perfect agreement and -1 is perfect disagreement. We use this when we have grade inflation problem.
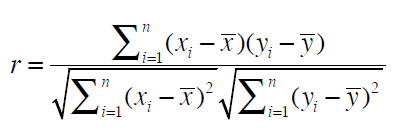
What is grade inflation? It means users are not consistent in giving the ratings. In below example Clara’s 4.75 is same as Robert’s 4 rating. In real time as well some people tend to give extreme ratings and some people never give extreme ratings and because of this an item (rockband in this case) which is extremely good might get ratings between 4-5 which are all same. And this problem is addressed with pierson coefficient.
| Blues traveler | Norah Jones | Phoenix | The Strokes | Weird Al | |
| Clara | 4.75 | 4.5 | 5 | 4.25 | 4 |
| Robert | 4 | 3 | 5 | 2 | 1 |
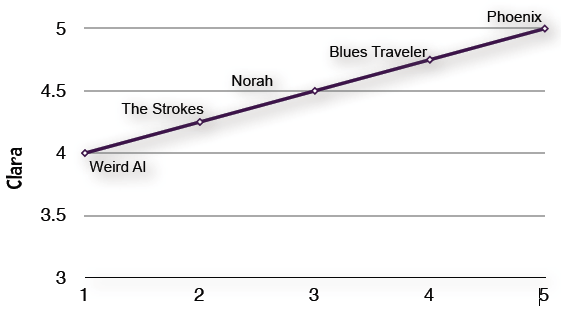
Jaccard Similarity
Data points in Jaccard Similarity are sets rather than vectors. Sometimes the equality of certain values does not mean anything and this problem is addressed with Jaccard Similarity.
What is set? Collection of unordered elements {a,b}
What is Cardinality? It counts number of elements in A and is denoted by |A|
Intersection of sets? Elements common in both datasets A and B
Union of Sets? All elements present in both sets.
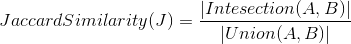
Illustration of iTune songs ordered by number of plays.
Problem Stmt: find similar songs in iTunes
Say, my top track is Moonlight Sonata by Marcus Miller with 25 plays. Chances are that you have played that track zero times. In fact, chances are good that you have not played any of my top tracks. In addition, there are over 15 million tracks in iTunes and I have only four thousand. So the data for a single person is sparse since it has relatively few non-zero attributes (plays of a track). When we compare two people by using the number of plays of the 15 million tracks, mostly they will have shared zeros in common and it doesn’t indicate the similarity between the users. On the other hand, if both users listened to the same song (a value of 1 for each), it is implied that the users have many similarities. In this case, equality of 1 should carry a much higher weight than equality of 0.
There are other distance measures for sequences (Time Series), network nodes(Sim Rank, Random Walk), population distribution(KL Divergence) which I will be covering in later posts.
REFERENCES
http://www.cse.msu.edu/~pramanik/research/papers/2003Papers/sac04.pdf
https://en.wikipedia.org/wiki/Cosine_similarity
http://dataaspirant.com/2015/04/11/five-most-popular-similarity-measures-implementation-in-python/

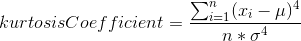
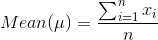
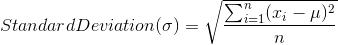



{kind=link}
Recent Comments