Spark Architecture
February 18, 2017 Leave a comment
Spark can be launched in different modes and each of this mode has different architecture.
- Local: Single JVM
- Standalone: from datastax (Static Allocation)
- YARN: from Hadoop (Dynamic Allocation)
- Mesos: Spark’s own Arch (Dynamic Allocation)
In these, 2,3,4 are distributed architectures. Standalone and Mesos architectures are similar to that of YARN.
https://tekmarathon.com/2017/02/13/hadoop-2-x-architecture/
In YARN, there are two different modes
- Spark YARN Client Mode Architecture: This is for Spark in Scala/Python shell (aka Interactive Mode). Here Spark Driver will be run in the Edge Node and if the Driver Program is killed or edge node crashes, the application gets killed.
- Spark YARN Cluster Mode Architecture: This is when user submits spark application using spark-submit. Here the Spark Driver is initiated inside the Application Master.
Unlike Hadoop Driver Program, Spark Driver is also responsible for
- DAG Scheduler and Task Scheduler: Once Executors are launched inside Containers, they will have direct communication with this Scheduler. This play far more important role than that of the YARN Scheduler in Spark Applications.
- Spark UI: UI with application DAG, Jobs and Stages are all served by the Spark Driver.
Spark Terminology – Nodes, Containers, Executors, Cores/Slots, Tasks, Partitions, Jobs, Stages
- Spark cluster can be formed with ‘n’ Nodes.
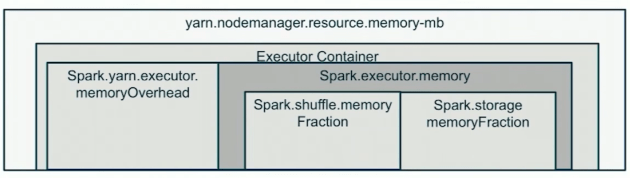
- Each Node can have 1+ containers. Number of containers are decided based on the min and max container memory limits in yarn-site.xml.
- Each Container must have exactly 1 Executor JVM.
- Each Executor can have 1+ Slots (aka Cores). The minimum slots required for Spark application are 2. Recommended range is between 8-32. We can choose a maximum of 2-3x times actual physical cores on a node.
- Tasks are run inside the Slots.Task is a unit of work assigned to Executor core/slot by the Task Scheduler.
- Partition is a block of data(like blocks in HDFS file). Spark RDD is split into 1+ partitions. Each Partition requires one thread of computation (aka Task) and hence an RDD with ‘n’ partitions requires ‘n’ Tasks to perform any Transformation.
- Jobs: A Spark Application is split into ‘n’ Jobs based on number of Actions inside it. Basically for every Action a Job will be launched.
- Stages: A Job is divided into ‘m’ Stages. A Stage is a group that can be put together based on operations, for example: map() and filter() can put together into a stage. And this Stage is finally split into ‘n’ Tasks.
















{kind=link}
Recent Comments