A framework for hypothesis spaces and learning algorithms
November 8, 2015 Leave a comment
Framework for hypothesis spaces
Key factors to understand the hypothesis space
- Size: Is the hypothesis space fixed in size (like Naïve Bayes) or variable in size (like Decision Trees)
- Fixed size spaces are easier to understand, but variable size spaces are more useful.
- Variable size spaces introduce the problem of overfitting.
- Randomness: Is each hypothesis ‘Deterministic’ or ‘Stochastic’? this effects how we evaluate hypothesis.
- With deterministic hypothesis, the training example is consistent, i.e, correctly predicted OR inconsistent, i.e, incorrectly predicted (ex: spam/non-spam detection)
- With stochastic hypothesis, the training example is more likely or less likely.
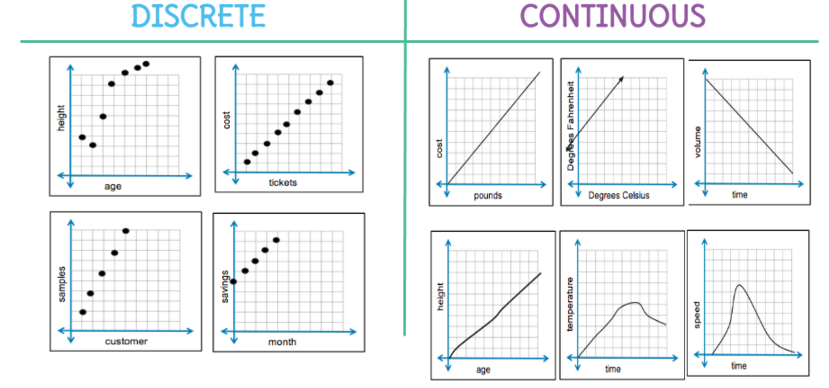
- Parameterization: Is the hypothesis described by set of symbolic (discrete) choices OR continuous parameters?
Framework for Learning Algorithms
Key factors to understand the learning algorithms
- Search Procedure
- Direct Computation: Solve for the hypothesis directly
- Local Search: Start with initial hypothesis and make small improvements until local optimum.
- Constructive Search: We start with empty hypothesis and gradually add structure to it.
- Timing
- Eager: Analyze training data and construct explicit hypothesis (Decision Trees)
- Lazy: Store the training data and wait till the testing data is presented and then construct the adhoc hypothesis to classify the test instance (KNN Algo).
- Online vs Batch Learning
- If the data changes very often (like stock market prediction), we need online learning
- If the data does not change much overtime (like drug analytics), then we need batch learning. This is more expensive.

Recent Comments